AI/ML Terms Explained Simply - Part2

This post is a continuation from the previous one explaining basic terms in the AI/ML space. In this post, we cover the key terms like model training, overfitting, underfitting, tokenization, embeddings and Inference.
To train a model, whether it’s a basic regression model or a massive LLM, we go through a process called model training. This is where we feed data (with or without labels) into the model, which then adjusts its internal parameters to minimize errors in prediction. The goal is to configure the model so it performs well not just on training data, but also on new, unseen data. Once this training phase is complete, the model is ready for inference, applying what it has learned to make real-world predictions.
However, things don’t always go smoothly. A model may suffer from overfitting, where it memorizes the training data, including all its quirks, so well that it fails to generalize to new data. On the flip side, underfitting happens when the model is too simple or not trained enough to capture meaningful patterns. Both problems hurt model performance and require careful tuning to fix.
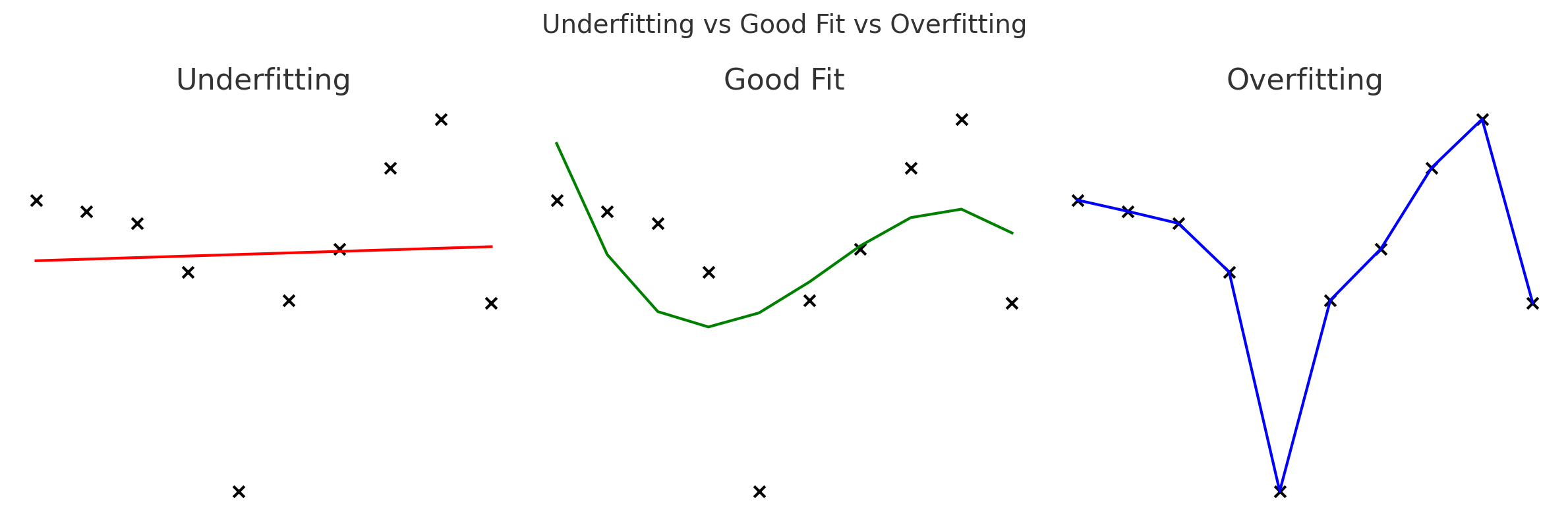
To avoid these pitfalls, data is often split into three sets: training, validation, and test. The training set helps the model learn, the validation set is used to tune parameters and monitor overfitting, and the test set evaluates how well the model generalizes to entirely new data.
When working with language data, tokenization is a crucial first step. It breaks down text into manageable pieces, usually words or subwords, so the model can process them. For example, the sentence “AI is powerful” would be split into individual tokens: [“AI”, “is”, “powerful”]. These tokens are what the model actually “sees” and learns from.
Once text is tokenized, it often needs to be transformed into a numerical format through embeddings. An embedding is a dense vector that captures the meaning and context of a word, phrase, or item in a way that allows the model to compare similarities. Words like “king” and “queen” would have similar embeddings because of their related meanings. Embeddings help bridge the gap between human language and machine logic.
Inference is the stage where a trained model is put to work. Whether it’s a chatbot responding to a query or an image recognition system classifying pictures, inference is the real-time application of everything the model has learned. This phase needs to be fast, reliable, and scalable, especially in production environments.
Evaluating how well a model performs requires the use of metrics. Accuracy is the simplest, what percentage of predictions were correct overall. Precision tells us how many of the model’s positive predictions were actually correct. Recall measures how many actual positive cases the model successfully identified. When you need a balance between precision and recall, the F1 Score is often used. In binary classification tasks, ROC-AUC is a helpful metric that shows how well the model separates classes regardless of threshold. These metrics offer different perspectives and are chosen based on what’s most important to your use case.
At the core of training lies the loss function. It’s a mathematical formula that measures the gap between the model’s predictions and the actual outcomes. During training, the model tries to minimize this loss. Different problems use different loss functions, for example, cross-entropy for classification tasks and mean squared error for regression. Monitoring the loss on both training and validation data helps ensure the model is learning effectively without overfitting.
Bias is another critical factor. If the training data is skewed or the model learns unfair associations, it can lead to biased outcomes that disadvantage certain groups. This can happen at various stages, from data collection to labeling, and needs to be actively managed. Addressing bias is essential for building ethical and trustworthy AI systems.
Finally, there’s the question of explainability. As models grow more complex, especially with deep learning and LLMs, it becomes harder to understand how they make decisions. Tools like SHAP and LIME help make predictions more interpretable by showing which inputs influenced the output most. For many applications,especially in finance, healthcare, or law, this transparency is just as important as accuracy.
Together, these concepts form the building blocks of modern AI. While the ecosystem is vast and constantly evolving, understanding these core ideas helps demystify how intelligent systems are built, trained, evaluated, and deployed in the real world.