LLM Evaluation Is a Program Management Problem
There is a moment every AI team eventually reaches. The model is performing reasonably well in testing. The prompts have been tuned. The retrieval pipeline is connected. Someone senior has asked for a status update, and the honest answer - the one nobody wants to give - is: we don't really know how well it's working.
That moment is not a model problem. It is not an engineering problem. It is a program management problem.
LLM (Large Language Model) evaluation - the discipline of measuring whether an AI system actually does what it is supposed to do - is one of the most technically sophisticated and simultaneously most organizationally neglected challenges in AI deployment today. The research papers discuss metrics and benchmarks. The engineering blogs discuss prompt frameworks and retrieval pipelines. Almost nobody talks about what it takes to run evaluation as an ongoing, coordinated, cross-functional program. And that gap is where AI projects quietly fail.
This piece is about that gap.
What LLM Evaluation Actually Is (And Why It Is Hard)
Traditional software is deterministic. A function either returns the right value or it doesn't. Testing tells you which. If you write a function that calculates sales tax, you can test it against a hundred inputs and know with certainty whether it is correct. The test either passes or it fails. There is no in-between.
LLMs are probabilistic. The same prompt, run twice, may produce slightly different outputs. But the more important problem is not the variation - it is the nature of what you are evaluating.
Consider an example- You are building an AI assistant for a financial services company. A user asks: "What should I consider before withdrawing from my 401(k) early?"
Run that prompt twice and you might get two responses that are both fluent, both confidently written, and both structured as helpful numbered lists. One mentions the 10% early withdrawal penalty, the tax implications, and the impact on compound growth. The other mentions the penalty and the taxes, but frames early withdrawal as more straightforward than it is - omitting hardship exceptions, the difference between Roth and traditional accounts, and state tax variations. A user reading either response would feel informed. One of them is subtly incomplete in ways that could lead to a costly mistake.
Most automated metrics won’t catch this reliably. A metric that scores by word overlap will compare both responses to a reference answer - but who wrote the reference, and did they cover every edge case? The response that passes every automated check is still the one a domain expert would flag as insufficient.
Now compound that across an application handling thousands of queries a day, across dozens of topic areas, with users making real decisions based on what the model tells them. The failure mode is not dramatic. The model does not crash. It returns something that looks right, reads well, and is wrong in a way that takes expertise to catch - and may never be caught at all if the evaluation program is not designed to look for it.
This is what makes LLM evaluation categorically different from traditional software testing. The question is not just "did it work?" The question is "how wrong could it be, in ways we haven't anticipated, at a scale we cannot manually review?" That is not a testing problem. It is a program design problem.
The Evaluation Stack: Three Layers, Three Different Problems
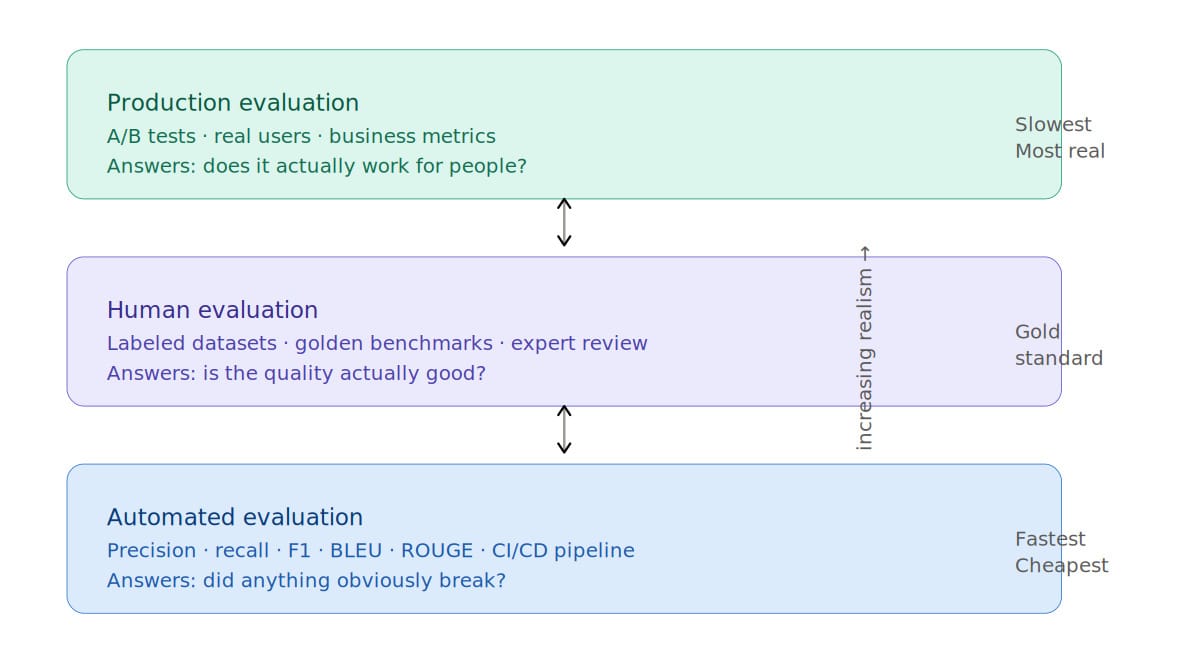
Automated Evaluation
Automated evaluation is the foundation. It is fast, repeatable, and relatively cheap. It runs after every significant change and catches obvious regressions before they reach users.
Take the 401(k) assistant. Suppose you add a safety layer that flags responses likely to contain incomplete tax guidance before they reach the user. Precision tells you how often the model's positive predictions are correct - of all the responses it flagged as incomplete, how many actually were? Recall tells you how many of the actual positives it catches - of all the genuinely incomplete responses, how many did it flag?
Neither alone is sufficient. A model that flags every single response as incomplete has perfect recall - it never misses a bad answer - but it has also flagged all the good ones, making the filter useless. A model that flags only the most obvious cases has decent precision but terrible recall. It forces a reckoning: you cannot hide behind one number while the other quietly fails.
For text generation, evaluation gets murkier. The most commonly used metrics - BLEU, borrowed from machine translation, and ROUGE, commonly used for summarization - work by comparing the model's output to a reference answer word by word, checking how much they overlap.
The problem is they were designed for tasks where there is a known correct answer. A French sentence has a right translation. A news article has a reasonable summary. But in an open-ended generation, there is no single right answer. Ask ten good writers to explain early 401(k) withdrawal and you get ten different responses - different structure, different wording, different examples - all of them useful. A metric that scores by word overlap will penalize nine of them simply for not matching the reference. It is measuring the wrong thing entirely.
Human Evaluation
Human evaluation is slower, more expensive, harder to scale, and - for most of the things that actually matter - irreplaceable.
No metric will tell you that your 401(k) response was technically accurate but condescending to a first-time investor, or that it covered the rules correctly but buried the most important point three paragraphs down. Humans will. And when you collect enough of those human judgments, patterns emerge: the responses that work tend to be accurate, clearly structured, appropriately detailed, and consistent with what the source material actually says. These qualities can fail independently. A response can be accurate but badly structured. Consistent but irrelevant. Fluent and completely wrong. A single score misses this.
Over time, human review produces something valuable: a set of real examples, graded by people who know what good looks like, that becomes the standard your system is held to. Teams call this a golden benchmark. It is the institutional memory of quality - the thing you run new changes against to check that nothing has gotten worse.
The catch is that it ages. The tax rules change. Users start asking questions in ways you didn't anticipate. A benchmark built six months ago may no longer reflect what good looks like today. Keeping it current is not a one-time project. It is an ongoing responsibility - which is, again, a program management problem.
Production Evaluation and A/B Testing
Most organizations implement this layer last. It is probably worth thinking about earlier.
Your golden benchmark tells you how the system performs in controlled conditions. Production tells you how it performs on real people with real problems. The gaps tend to be humbling. Users phrase things differently than your test cases anticipated. A correct answer that takes too long is still a bad experience. Small variations in how a query is worded can surface different documents from your retrieval pipeline in ways nobody thought to model in the lab.
A/B testing is a useful way to formalize this - rather than asking whether version B is better in the abstract, you ask whether it drives better outcomes with real users. What you measure depends on your application: task completion rates, customer satisfaction, escalation rates, support resolution times. These are not AI metrics. They are business metrics. Which is worth pausing on, because it suggests evaluation reaches further than most engineering teams expect.
Why This Is a Program Management Problem
LLM evaluation requires sustained, coordinated effort across multiple functions, against competing priorities, with ambiguous success criteria, over an indefinitely long time horizon. That is the definition of a program management problem.
Here are the specific ways it tends to break.
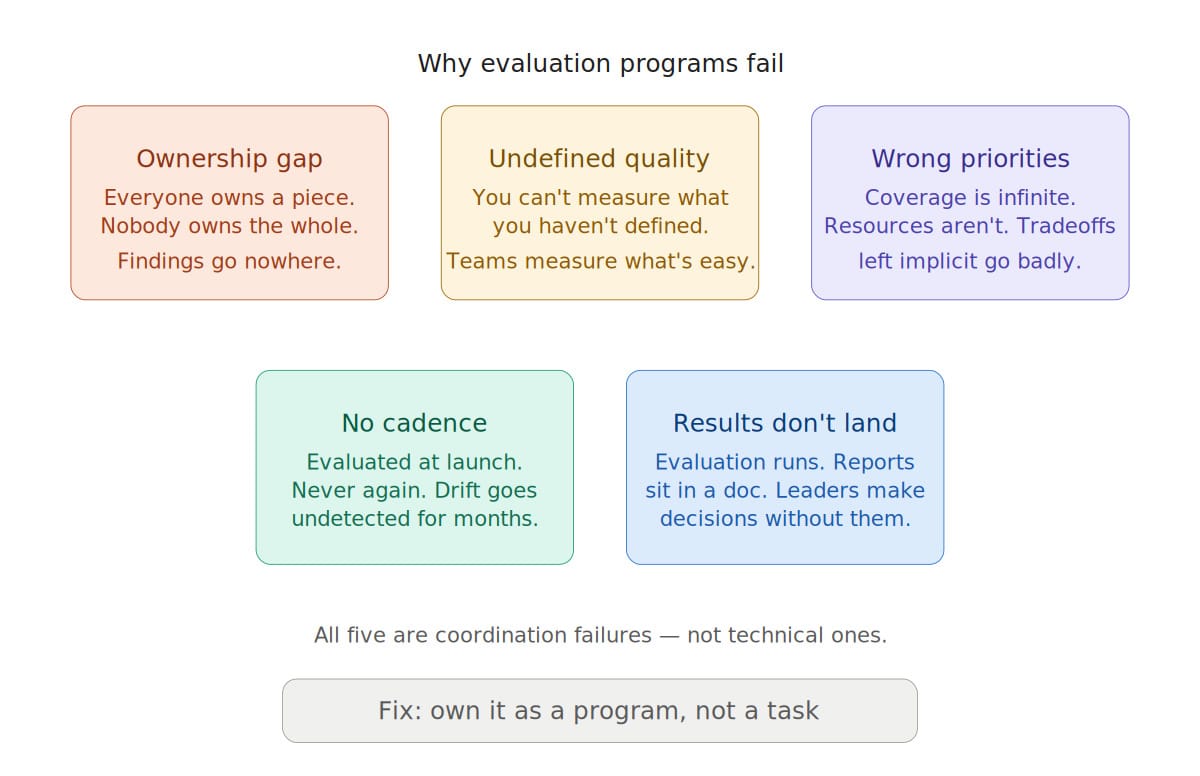
Ownership Gaps
The most common failure mode is that nobody actually owns evaluation end-to-end. Engineering owns the build. ML owns model quality. Product owns user experience. QA, where it exists, is running playbooks inherited from traditional software that don't quite fit. Everyone owns a slice. Nobody owns the whole.
So automated metrics pass, human review flags a problem, the problem doesn't reach anyone who can act on it, and three weeks later production satisfaction is declining with no one connecting the dots.
This is an organizational failure, not a technical one. The fix is equally organizational: someone needs to own the evaluation program with enough mandate and visibility to connect all three layers.
The Measurement Definition Problem
Before you can measure quality, you have to define it. This sounds obvious. It is surprisingly hard.
Does a correct response from your support chatbot resolve the user's issue, or just answer their stated question? Those are different things, and optimizing for one can quietly degrade the other. Does quality in a coding assistant mean code that runs, or code a senior engineer would be proud of? Also different things.
Getting to a shared definition requires product, domain experts, and technical teams to have some genuinely difficult conversations. And those definitions need revisiting as the product evolves and as you learn more about what users actually need.
This is where a program manager earns their keep - not by making the final calls on what quality means, but by running the process that produces those calls. Keeping the conversation moving, documenting what was decided and why, surfacing disagreements before they become crises, and making sure the resulting definitions actually show up in test cases rather than sitting in a slide deck somewhere.
The Prioritization Problem
Evaluation coverage is infinite. Resources are not.
You could evaluate factual accuracy, tone, safety, latency, citation quality, edge case behavior, and a dozen other things. You cannot do all of them well. So you have to choose.
The right choice depends on your application and your users. A medical information tool and an internal drafting assistant have almost nothing in common when it comes to evaluation priorities. For one, factual accuracy and safety are existential. For the other, speed and convenience probably matter more than occasional imprecision.
The trap is leaving these tradeoffs implicit. When nobody decides what matters most, teams default to measuring what is easy to measure. Easy and important are rarely the same thing. Making the call explicitly, documenting it, and revisiting it as the product evolves is a program management function.
The Cadence Problem
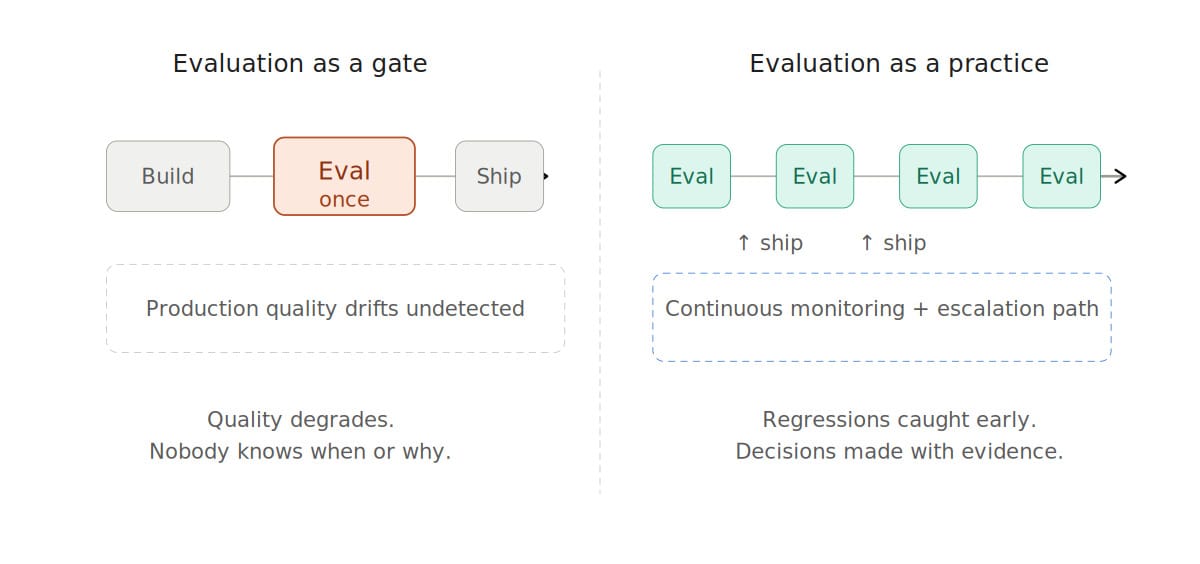
Here is a pattern that plays out more often than anyone likes to admit. A team runs a solid evaluation before launch. It passes. They ship. Six months later something feels off - users are complaining, satisfaction is sliding - but nobody can pinpoint when it started or why, because nobody ran a structured evaluation after the launch one.
The thing is, LLMs drift. User behavior changes. The questions people ask evolve. A system that was working fine at launch can quietly degrade through a dozen small changes, none of which would have triggered an alarm on its own.
Evaluation is not a gate you pass through once. It is more like a recurring health check. And like any recurring activity, it only happens if someone owns it - the calendar, the process, the reporting, and the conversation that happens when results start slipping.
The Stakeholder Alignment Problem
The last failure mode is the quietest one. The evaluations ran. The results exist. Nobody who makes decisions ever saw them.
This happens when evaluation stays inside the technical team - reports written by engineers, read by engineers, acted on by engineers. Meanwhile product leadership is making roadmap calls based on gut feel and user anecdotes. Legal is making risk calls without knowing what the safety evaluations actually showed. Business stakeholders are signing off on launches without a clear picture of how reliable the system actually is.
Getting evaluation results into the hands of people who can act on them is partly a communication problem and partly a coordination problem. Someone needs to translate a drop in evaluation scores into something a product leader or a legal team can reason about. Someone needs to make sure the right findings reach the right people before the decision gets made, not after. That someone is usually a program manager.
What Good Actually Looks Like
So what does a well-run evaluation program look like in practice?
Named ownership- Someone owns the evaluation program - not every individual eval, but the methodology, cadence, reporting, and escalation path. In practice this is often a (T)PM working closely with ML and product.
Written quality definitions- Before any tooling gets built, there is a documented definition of what quality means for this specific application, with tradeoff decisions recorded. It gets revisited on a schedule, not just when something breaks.
A tiered architecture- Automated metrics run continuously. Human evaluation runs on a cadence. Production telemetry is live from day one. A/B tests are planned, not reactive.
A living benchmark- The golden dataset is treated like a codebase - new cases get added as edge cases emerge in production, stale cases get retired, coverage gets audited.
A clear escalation path- When results degrade past a defined threshold, everyone knows what happens next: who gets notified, what decisions get paused, what has to improve before the team moves forward.
Stakeholder alignment- Evaluation results get translated into language that product, legal, and business stakeholders can reason about. Not a technical readout - a program health update.
The Bottom Line
LLM evaluation is technically complex. Building good benchmarks, designing test cases, instrumenting production telemetry - these require real expertise.
But the failure mode that kills most evaluation programs is not technical. It is organizational. Nobody owns it. Quality never gets defined. Evaluations run once and fade. Results never reach the people making decisions.
The good news is you do not need to get it all right from the start. Start with the failure modes that matter most for your specific application, measure those well, and build from there. What matters most is itself something you figure out over time - through user feedback, unexpected failures, and the slow accumulation of knowing how your system actually behaves in the wild.
Perfection is not the goal. A consistent practice of measuring what matters, catching degradation early, and improving is. That is a program management capability. It is learnable.
For Further Reading-
- LLM Evals: Everything You Need to Know - https://hamel.dev/blog/posts/evals-faq/
- Using LLM-as-a-Judge - https://hamel.dev/blog/posts/llm-judge/
- Lenny's Newsletter interview - https://www.lennysnewsletter.com/p/why-ai-evals-are-the-hottest-new-skill
- Anthropic: Demystifying Evals for AI Agents - https://anthropic.com/engineering/demystifying-evals-for-ai-agents
- Pragmatic Engineer: A Pragmatic Guide to LLM Evals - https://newsletter.pragmaticengineer.com/p/evals
~Amrita Thavrani
P.S If you have come this far - thank you! Please consider subscribing at whatwasthatagain.com for posts where I break down AI concepts for PMs and beyond.
Member discussion